Natural Language Voice Assistants with Sentence Transformers
In the era of AI voice assistants, most systems rely heavily on the cloud for speech recognition, raising concerns about data privacy, security, and the need for constant internet connectivity. To address these challenges, AI-driven offline voice assistants are used. Such offline voice assistants are especially crucial in automotive systems, where reliable voice control over in-car functions must remain available even in areas with poor cellular coverage.
In this article, we will discuss a challenge we faced while implementing natural language commands and the solution we adopted to overcome it.
Background: AI-driven Offline Voice Assistant
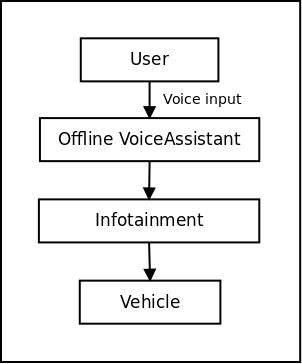
In our setup, we have a Linux-based Raspberry Pi and an Android-based CAVLI CQS290 EVK. The voice assistant is running on the RPi, and it’s handling the voice input data from the user controls the infotainment system running on the EVK. The voice input is converted to text using the OpenAI Whisper ASR model. The voice assistant uses the converted text to control features like Hotspot, Airplane mode, Wi-Fi, Bluetooth, Lights, etc. The following is a block diagram that shows various components of the AI-driven Offline Voice Assistant.
The following is a photo of the actual setup in action.

The Problem
Automatic Speech Recognition (ASR) can be error-prone for multiple reasons.
For example, when we said enable Wi-Fi, we frequently received enable
wife, enable life, or just Wi-Fi. We first tried to address these
issues using elaborate nested IF conditions as shown in the pseudocode below.
# Check for Wi-Fi commands
IF response contains "wif" OR "wi-fi" OR "life":
IF response contains "on" OR "enable":
CALL set_wifi_state(True)
ELSE IF response contains "off" OR "disable":
CALL set_wifi_state(False)
ELSE:
PRINT "Unknown audio request: response"
# Check for LED/light commands
ELSE IF response contains "led" OR "light" OR "lady":
IF response contains "on" OR "enable":
CALL set_given_pin_high(pin)
ELSE IF response contains "off" OR "disable":
CALL set_given_pin_low(pin)
ELSE:
PRINT "Unknown audio request: response"
# Handle unrecognized commands
ELSE:
PRINT "Unknown audio request: response"
While this works, it is neither scalable nor elegant. It is more of a workaround rather than a solution.
In the second iteration of our implementation, we were also given the additional requirement to support "Natural language commands". So a user can say any of the following, and the Wi-Fi would be turned on.
-
Turn on Wi-Fi
-
Enable Wi-Fi
-
Please turn on the Wi-Fi
-
Wi-Fi on
-
Wi-Fi enable, please!
We briefly mulled over using a full-blown LLM-based agent with tool calling to get this done. But it was clearly evident that LLMs would be an overkill, because the compute needed for running an LLM, within the system, was just not available.
So we had the following problems at hand.
-
Incorrect recognition of domain-specific terms.
-
Words introduced by background noise.
-
Uncertainties are introduced by a human speaker.
-
Natural language commands.
The first issue was solved by fine-tuning the model with domain specific terms. (How we did this is discussed in detail in a separate article Lessons from Fine-Tuning Whisper for Tamil Voice Commands.)
While researching how to handle natural language commands, we stumbled upon Sentence Transformers! What’s more, Sentence Transformers can also, to a certain extent, compensate for the problems 2 and 3. We will dive into the details of how this works in the subsequent sections of this article.
The Solution
To understand how Sentence Transformers works and how we solved our problem using Sentence Transformers, we need to understand what word embeddings are.
Word Embedding
Traditionally in computers, a word is represented as a sequence of ASCII codes, with each code representing a character in the word. This is useful for printing the word, getting the word as input from the user, etc. But this representation does not help with understanding the meaning of the word. So the ASCII representation of "dog" and "pup" are completely different and there is no indication that they are in any way similar.
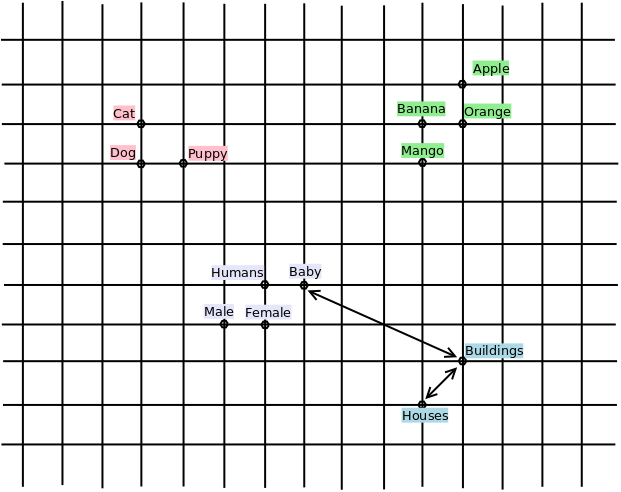
A word embedding is a way or representing a word as numerical vectors in a fixed-dimensional space. This transformation allows computers to understand what the word represents. Each dimension of the vector might be used to represent some information about the word. The beauty of this representation is that words with similar meanings are closer to each other in this space. For example, “Buildings” and “Houses” might be closer than “Buildings” and “Baby”.
For LLMs to process words, they are represented as token embeddings, which are very similar to word embeddings that we have discussed. These token embeddings can have a dimension in the range 2048 to 12288. The following diagram shows what a 2 dimensional embedding would look like. Observe how similar words are clustered together.
Sentence Transformer
Now that we have a basic understanding of word embeddings. Let’s try to understand sentence embeddings. A sentence embedding is fixed-length vector representation (embeddings) of an entire sentence. These embeddings capture the meaning of a sentence, making them particularly useful for understanding natural language inputs, even when phrased differently or with slight pronunciation errors.
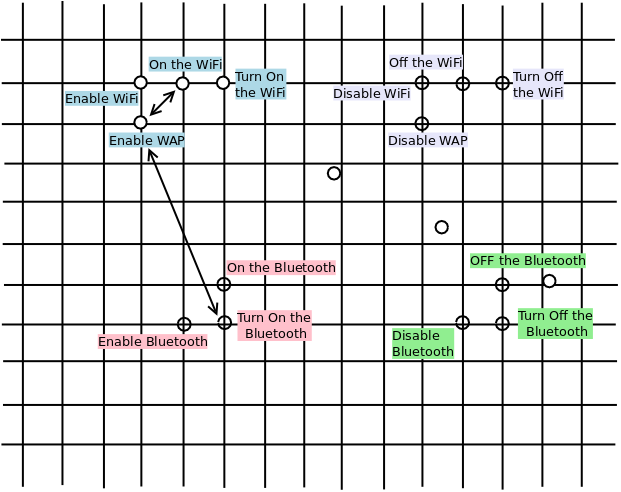
Sentences with similar meanings are closer to each other in this space. For example, “On the wifi” and “Enable WAP” might be closer than “Enable WAP” and “Turn on the Bluetooth”. This idea is captured in the following diagram, using a 2-dimensional sentence embedding.
A Sentence Transformer is a large language model that converts a sentence
or a paragraph into sentence embeddings. These models are very lightweight
compared to generative models. In our case, we used the LaBSE model from
the Sentence Transformers library. The model was developed by Google and
can work across 109 languages, including Tamil.
In our implementation, we convert predefined commands and user inputs into sentence embeddings using the Sentence Transformer model. We then find which predefined command is closest to the user input. This kind of matching is called semantic search. The closest command is then executed. The following code demonstrates how we implemented matching of user input to commands, using Sentence Transformers.
# Dependencies:
# pip install -U sentence-transformers
from sentence_transformers import SentenceTransformer, util
# Load pre-trained sentence transformer model
model = SentenceTransformer('sentence-transformers/LaBSE')
# Predefined commands in English
commands = [
"Enable Wi-Fi.",
"Disable Wi-Fi.",
"Enable Bluetooth.",
"Disable Bluetooth."
]
# Encode the commands once
cmd_embeddings = model.encode(commands)
# User Input in both Engilsh and Tamil
inputs = [
"Enable Wi-Fi",
"Please turn on the Wi-Fi",
"Disable Wi-Fi",
"Please turn off the Wi-Fi",
"வைஃபை ஆன் பண்ணு",
"ஆன் வைஃபை",
"வைஃபை ஆஃப் பண்ணு",
"ஆஃப் வைஃபை",
]
# Main loop for handling user's queries
for input in inputs:
# Encode the input
input_embedding = model.encode(input)
results = util.semantic_search(input_embedding, cmd_embeddings)
print(f"Input: {input}")
for result in results[0]:
cmd = commands[result['corpus_id']]
score = result['score']
print(f"\tCommand: {cmd}")
print(f"\tSimilarity Score: {score}")
# First result is the command that is closest to the user input
adjacent_command = commands[results[0][0]['corpus_id']]
print(f"'{input}' matches with '{adjacent_command}'\n")
Results and Further Work
With the use of Sentence Transformers and similarity search, when the user
gives the command can you please on the wifi, not part of the predefined
command list, the meaning of the command is used to identify the closest
predefined command, Enable wifi. Here is a section of the output for
the above code. Observe the similarity score for input and each of the
available commands. Also note how the LaBSE model is able to work across
languages!
... clip ...
Input: Please turn off the Wi-Fi
Command: Disable Wi-Fi.
Similarity Score: 0.8216402530670166
Command: Enable Wi-Fi.
Similarity Score: 0.7304953336715698
Command: Disable Bluetooth.
Similarity Score: 0.5569100379943848
Command: Enable Bluetooth.
Similarity Score: 0.45534107089042664
'Please turn off the Wi-Fi' matches with 'Disable Wi-Fi.'
Input: வைஃபை ஆன் பண்ணு
Command: Enable Wi-Fi.
Similarity Score: 0.7483900189399719
Command: Disable Wi-Fi.
Similarity Score: 0.7294138669967651
Command: Enable Bluetooth.
Similarity Score: 0.4260103404521942
Command: Disable Bluetooth.
Similarity Score: 0.4214862287044525
'வைஃபை ஆன் பண்ணு' matches with 'Enable Wi-Fi.'
... clip ...Use of similarity search also helps with dealing with missed out words, and words added by background noise, if present. Making the solution overall more robust.
Despite all these benefits, there are caveats with Sentence Transformers
too. While there is a difference in similarity score between Disable
Wi-Fi and Enable Wi-Fi. The difference is small about 0.09. And sometimes
the model can return incorrect results with tricky inputs.
We found that larger embedding models like Qwen/Qwen3-Embedding-0.6B are able
to create a larger difference in the similarity scores. But these models are
comparatively slower and need more compute.
Some solutions that we could consider are.
-
Fine-tuning the Sentence Transformer model
-
Getting confirmation from the user
Also, when a command involves an argument, Sentence Transformers alone are not sufficient. For example, in the case of a command like "Set the AC temperature to 25", it is necessary to extract the temperature argument from the command. Looks like Slot Filling models need to be trained for this purpose. This is something that we will be taking up in the future.
Concluding Notes
Hope this article provided an overview of how embedding works and in-turn, how sentence embeddings can be used for implementing command matching in voice assistants.
At Zilogic Systems, we are working extensively to bring AI to the automotive domain, both in terms of implementing AI-based solutions within the vehicle and for testing automotive systems. If you are interested in integrating AI into your automotive ECUs or using AI in improving automotive ECU testing, please get in touch with us at sales@zilogic.com